
Quick take: The fraud detection AI market hit $14.7 billion in 2025 and is projected to reach $65 billion by 2034, according to Fortune Business Insights. That growth is driven by a stark reality: synthetic identity fraud, deepfake-enabled account takeovers, and AI-generated phishing have outpaced the rule-based systems most organizations still rely on. Building a custom fraud detection model — rather than licensing an off-the-shelf platform — gives you control over detection logic, reduces false positive rates by 60-95%, and lets you train on your own transaction data. This guide covers how to do it, what it costs, and where teams get it wrong.
JPMorgan Chase prevented $1.5 billion in fraud losses in 2024 using custom AI models built on its proprietary transaction data. Mastercard’s Decision Intelligence platform processes transactions in under 50 milliseconds and has improved fraud detection rates by up to 300% for partner banks. Stripe cut fraud rates by 30% with its Radar system trained on billions of transactions across its network. These results came from custom-built systems, not vendor platforms plugged in out of the box.
The difference matters. Off-the-shelf fraud detection tools generalize across industries. A custom model learns your specific transaction patterns, customer behaviors, and fraud vectors. For organizations processing more than 10,000 transactions per day, the ROI math favors building.
Why Rule-Based Systems Fail in 2026
Traditional fraud detection relies on static rules: flag transactions over $10,000, block purchases from certain countries, require step-up authentication for new devices. These rules worked when fraud was manual and predictable. They do not work against generative AI.
Deepfake-enabled fraud tripled in the United States in 2025, causing an estimated $1.1 billion in losses according to Deloitte’s Center for Financial Services. Fraudsters now use AI to generate synthetic identities that pass KYC checks, clone voices for social engineering, and create fake documents that bypass optical character recognition systems. Account takeover fraud surged 24% year-over-year, costing consumers $15.6 billion according to Javelin Strategy & Research.
Rule-based systems cannot adapt to these attacks because they require human analysts to identify new patterns and manually write new rules. By the time a rule is deployed, fraudsters have moved on to the next attack vector. Custom AI models detect anomalies in real time by learning from the data itself, not from predetermined thresholds.
The False Positive Problem
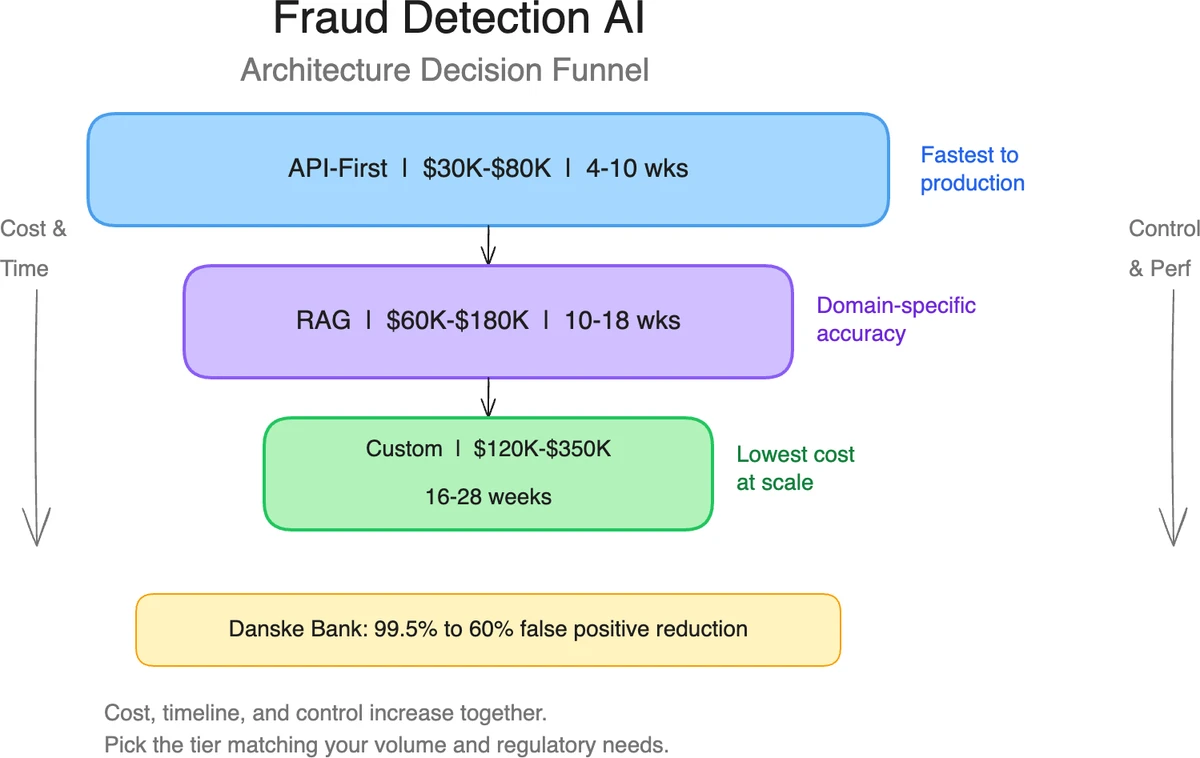
The bigger operational cost is often not fraud itself but false positives. Danske Bank reported that 99.5% of its fraud alerts were false positives before implementing a custom AI model. After deployment, false positive rates dropped by 60%, freeing hundreds of analyst hours per week. JPMorgan reported reducing false positives by 95% in its anti-money laundering operations after deploying custom AI.
False positives create direct revenue loss. Every legitimate transaction flagged and blocked is a customer who may not come back. Mastercard estimates that false declines cost merchants $443 billion globally per year — more than 13 times the cost of actual fraud.
Architecture Patterns for Custom Fraud Detection
Three architecture patterns have emerged as production-proven for fraud detection AI. The right choice depends on your transaction volume, data maturity, and latency requirements.
Pattern 1: Graph Neural Networks for Relationship Analysis
Graph Neural Networks (GNNs) model transactions as a network of relationships between entities — accounts, devices, IP addresses, merchants, and beneficiaries. This makes them effective at detecting fraud rings, money laundering networks, and synthetic identity clusters that appear unrelated in tabular data.
Featurespace (Cambridge, UK) uses GNN-based models in its ARIC platform, deployed at banks including HSBC and NatWest. Their system reduced authorized push payment (APP) fraud losses by 90% at Eika Gruppen, a Norwegian banking group. Amazon and PayPal have published research on GNN architectures for detecting coordinated fraud across their platforms.
| Component | Technology | Latency |
|---|---|---|
| Graph construction | Neo4j or Amazon Neptune | Batch (minutes) |
| Feature extraction | PyTorch Geometric or DGL | Sub-second |
| Inference | ONNX Runtime on GPU | 10-50ms |
| Feedback loop | Kafka + labeled outcomes | Continuous |
Best for: Organizations with complex entity relationships, payment networks, or marketplaces where fraud involves coordination between multiple accounts.
Pattern 2: Transformer-Based Sequence Models
Transformer architectures (the same architecture behind GPT and Claude) excel at modeling sequences of events over time. For fraud detection, this means analyzing a user’s transaction history as a sequence and flagging deviations from their established pattern.
Research published in 2025 demonstrated hybrid GNN-Transformer models achieving 99% accuracy on fraud detection benchmarks, outperforming both standalone GNNs and traditional gradient-boosted tree models. The transformer component captures temporal patterns (a user who always buys coffee at 8am suddenly making a $5,000 purchase at 3am), while the GNN component captures relationship patterns.
Best for: High-volume transaction processors where behavioral modeling matters — card-not-present fraud, account takeover detection, and recurring payment anomalies.
Pattern 3: Ensemble with Federated Learning
Federated learning allows multiple organizations to train a shared fraud detection model without sharing raw transaction data. Each participant trains a local model on their data, and only the model updates (not the data) are aggregated into a global model.
This approach has gained traction in banking consortiums. Research from 2025 shows federated learning models improve fraud detection accuracy by 15-30% compared to models trained on a single institution’s data alone, because they learn from a broader distribution of fraud patterns. Visa and Mastercard have both invested in federated learning infrastructure for their payment networks.
Best for: Organizations in regulated industries where data sharing is restricted, or consortiums that want to pool fraud intelligence without exposing customer data.
Implementation Roadmap
Building a custom fraud detection model follows a predictable timeline when scoped correctly. The critical variable is data readiness — teams with clean, labeled transaction histories move faster.
Phase 1: Data Assessment and Baseline (Weeks 1-4)
The first milestone is establishing what you are working with. This means:
- Auditing your transaction data for volume, completeness, and label quality (do you know which past transactions were fraudulent?)
- Measuring your current false positive and false negative rates to set a baseline
- Identifying the specific fraud types causing the most damage (ATO, synthetic identity, payment fraud, etc.)
- Selecting the architecture pattern based on your data characteristics
Most projects stall here because organizations overestimate their data quality. Expect to spend 40-60% of the project budget on data engineering if your transaction data is spread across multiple systems or lacks consistent labeling.
Phase 2: Model Development and Training (Weeks 5-14)
Development follows iterative two-week sprints:
Sprints 1-2: Feature engineering and initial model training. Build the data pipeline, engineer domain-specific features (transaction velocity, device fingerprinting, geolocation anomalies), and train the first model version.
Sprints 3-4: Model optimization and integration. Tune hyperparameters, benchmark against your baseline, integrate with your transaction processing pipeline, and implement the feedback loop for continuous learning.
Sprints 5: Shadow mode deployment. Run the model alongside your existing system without acting on its decisions. Compare its predictions to actual fraud outcomes to validate accuracy before going live.
Phase 3: Production Deployment and Monitoring (Weeks 15-20)
Production deployment requires:
- Real-time inference under 50ms (table stakes for payment processing)
- Fallback rules for model failures or edge cases
- Explainability layer (SHAP or LIME) for regulatory compliance and analyst review
- Monitoring for concept drift — fraud patterns change, and models degrade if not retrained
Plan for weekly or monthly model retraining. Fraud patterns shift faster than most ML domains, and a model trained on last quarter’s data can miss this quarter’s attack vectors.
What It Costs
Custom fraud detection AI development ranges from $40,000 to $250,000+ depending on scope. Here is a realistic cost breakdown based on project data from 2024-2025:
| Component | Cost Range | Timeline |
|---|---|---|
| Data assessment and preparation | $10,000-$40,000 | 2-4 weeks |
| Model development and training | $20,000-$120,000 | 6-10 weeks |
| Integration and deployment | $10,000-$50,000 | 3-5 weeks |
| Infrastructure (annual) | $12,000-$72,000 | GPU compute + storage |
| Maintenance and retraining (annual) | $20,000-$80,000 | 15-25% of dev cost |
Financial institutions using custom AI models report average savings of $7 million per year in prevented fraud losses and reduced operational costs, according to a 2025 McKinsey analysis of banking AI deployments. For a $150,000 implementation, that represents a payback period under 6 months.
The largest cost driver is data engineering, not model building. Organizations with clean, labeled data and modern data infrastructure can complete projects at the lower end of the range. Organizations that need to consolidate data from legacy systems, build labeling pipelines, or comply with data residency requirements should budget toward the upper end.
Regulatory Requirements You Cannot Ignore
The EU AI Act classifies fraud detection systems used in financial services as “high-risk AI,” with full compliance requirements taking effect August 2, 2026. This means:
- Explainability: You must be able to explain why a transaction was flagged. Black-box models that produce a fraud score without justification do not meet the standard. Implement SHAP (SHapley Additive exPlanations) or LIME (Local Interpretable Model-agnostic Explanations) from the start.
- Human oversight: Automated decisions that affect individuals require human review mechanisms. For fraud detection, this means analyst review queues for flagged transactions, not fully automated blocking.
- Bias testing: Models must be tested for discriminatory outcomes across protected characteristics. Transaction monitoring models can develop geographic or demographic biases if trained on skewed data.
- Documentation: Technical documentation of the model’s architecture, training data, performance metrics, and risk assessment must be maintained and available for regulatory audit.
Fines for non-compliance reach up to 7% of global annual turnover. In the US, Colorado and California have enacted state-level AI regulations with similar explainability and fairness requirements for automated decision-making in financial services.
Building explainability and fairness testing into the model from day one costs 10-15% more upfront. Retrofitting it after deployment costs 3-5x that amount and often requires retraining the model from scratch.
Frequently Asked Questions
What accuracy should a custom fraud detection model achieve?
Production models typically reach 85-95% precision (correctly identified fraud out of all flagged transactions) and 70-90% recall (fraud caught out of all actual fraud). The tradeoff between precision and recall depends on your tolerance for false positives versus missed fraud. Mastercard’s Decision Intelligence system achieves above 95% precision with sub-50ms latency. For most organizations, start by targeting a 50% reduction in false positives compared to your current system while maintaining or improving fraud catch rates.
How much labeled training data do I need?
GNN and transformer models require at least 100,000 labeled transactions to train effectively, with 500,000+ being ideal. The critical factor is the ratio of fraudulent to legitimate transactions — fraud is rare (typically 0.1-0.5% of transactions), so techniques like SMOTE oversampling or focal loss functions are needed to handle class imbalance. Stripe’s Radar model trains on billions of transactions across its network, which is part of why network-scale data produces better models than single-organization data.
Can I start with an off-the-shelf model and customize it later?
Starting with a vendor platform like Feedzai, Featurespace, or SAS and layering custom rules on top is a common approach for organizations that need to move fast. The tradeoff is reduced flexibility and higher long-term cost — vendor licensing typically runs $200,000-$1M+ annually for enterprise deployments, while a custom-built system costs more upfront but less over a 3-year horizon. Many organizations start with a vendor and migrate to custom once they have sufficient labeled data and internal ML capability.
How do I handle concept drift in production?
Fraud patterns change as attackers adapt to detection systems. Monitor model performance daily using metrics like precision, recall, and the rate of new fraud patterns not seen in training data. Retrain models on a weekly or monthly cadence using recent transaction data. Implement a champion-challenger framework where the production model runs alongside a newly trained model, and you promote the challenger when it demonstrates improved performance on a holdout dataset.
What infrastructure do I need for real-time fraud detection?
Real-time inference under 50ms requires GPU-accelerated serving (NVIDIA T4 or A10G instances on AWS/GCP), a feature store for low-latency feature retrieval (Feast, Tecton, or Redis), and a streaming pipeline (Kafka or Kinesis) for ingesting transactions. Budget $3,000-$6,000/month for infrastructure at moderate scale (100,000 transactions/day). At higher volumes, consider ONNX Runtime or TensorRT for model optimization to reduce per-inference cost.
Key Takeaways
- Custom fraud detection models outperform off-the-shelf platforms when you have sufficient transaction data (100,000+ labeled examples) and specific fraud patterns unique to your business
- Graph Neural Networks detect fraud rings and coordinated attacks; transformer models catch behavioral anomalies; federated learning enables cross-organization intelligence without data sharing
- False positives often cost more than fraud itself — Mastercard estimates $443 billion in false declines globally, and custom models reduce false positive rates by 60-95%
- Budget $40,000-$250,000 for development, with 40-60% of the budget going to data engineering, not model building
- EU AI Act compliance for high-risk fraud detection systems takes effect August 2, 2026 — build explainability (SHAP/LIME) and bias testing from day one
- Plan for weekly or monthly model retraining; fraud patterns evolve faster than most ML domains and models degrade without continuous learning
SFAI Labs


