
Project Overview
Strategy & Advisory
Agents
Automation & Integration
A personal growth startup relied on chat as the core product experience across B2C and B2B2C segments. As usage grew, latency became a direct product and retention risk—responses were slow, concurrency was constrained, and the backend architecture made scaling costly.
SFAI Labs partnered with the founding team to define a value-driven performance strategy that aligned product experience goals (speed, consistency, reliability) with technical execution. Using a lab acceleration model, we benchmarked end-to-end latency, identified bottlenecks across the LLM pipeline and infrastructure, and prioritized improvements with the highest time-to-value.
Within weeks, we implemented a production-grade optimization plan spanning async backend refactor, structured output enforcement, routing improvements, and parallel context gathering. This created a clear path to faster responses, higher throughput, and a more scalable foundation for ongoing AI product development.
By combining AI strategy, engineering execution, and commercialization alignment, the client gained a stronger user experience, better retention leverage, and a more cost-efficient architecture for scaling AI features.
Key Takeaways
Latency is product value
Async unlocks throughput
Routing reduces overhead
Structured outputs stabilize
Benchmarks drive velocity
Challenge
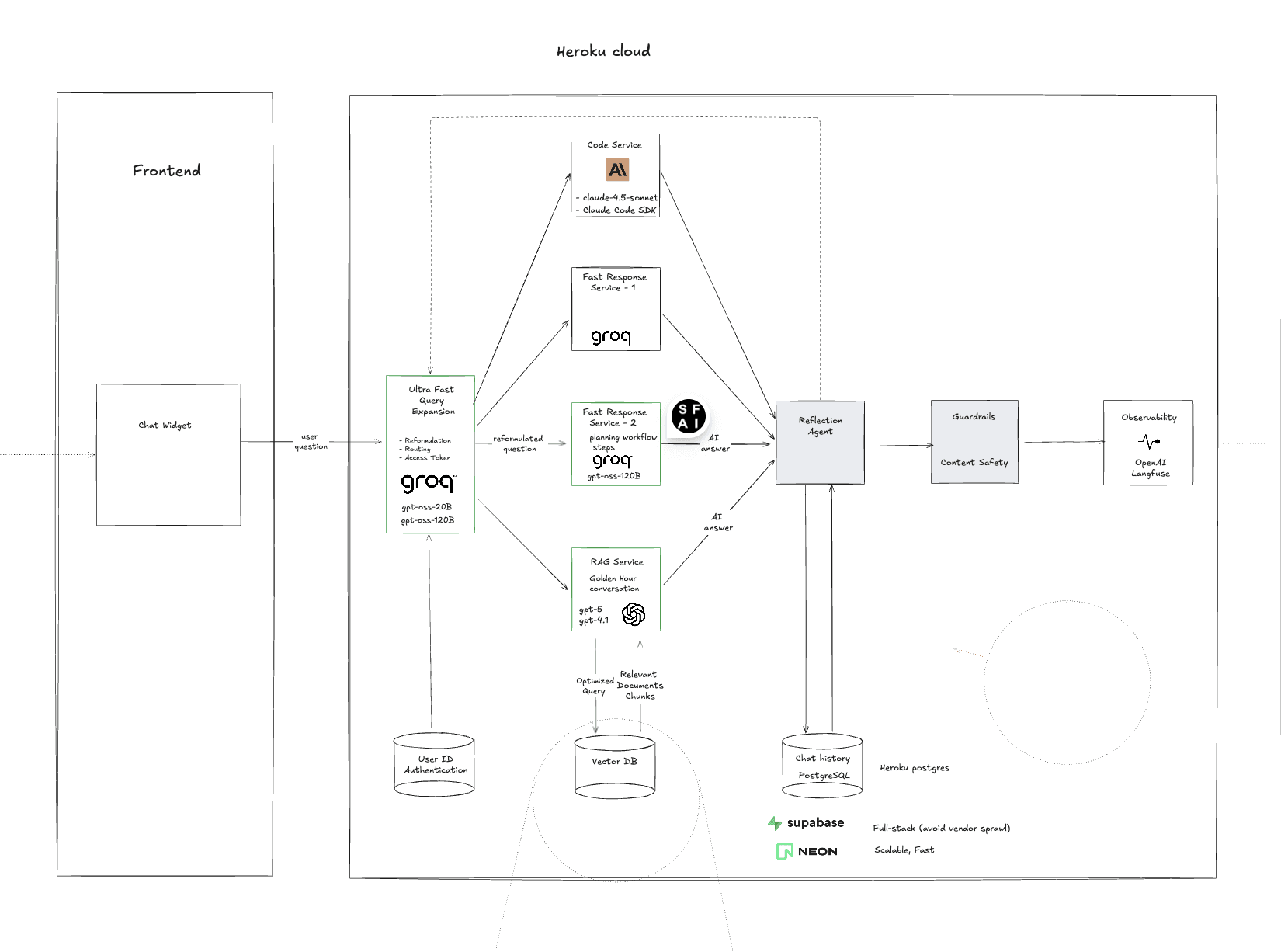
Chat response latency averaged ~4.5s and varied widely under load, degrading the core user experience. The existing synchronous architecture blocked workers during LLM calls, limiting concurrency and increasing infrastructure cost. The system also needed reliable structured outputs for downstream application logic, without forcing major frontend changes.
Strategy
We executed a performance-first AI product strategy focused on measurable outcomes: reduce latency, improve throughput, and preserve product behavior. The approach combined (1) benchmarking and instrumentation, (2) architectural refactor planning for async execution, (3) LLM pipeline improvements (routing + structured outputs), and (4) a scalable roadmap for reliability and growth.
Solution
We delivered a set of production optimizations across strategy, platform, and AI system design:
Introduced an async architecture path (FastAPI + async DB/Redis clients) while maintaining API compatibility and rollback safety
Implemented routing logic to reduce unnecessary prompt overhead and direct queries to the right workflow
Enforced structured outputs with explicit schemas to improve reliability and reduce parsing failures
Parallelized context gathering to overlap RAG retrieval with database/user context operations
Added a repeatable benchmark harness to measure improvements over time
Execution
Week 1: Baseline benchmarking and bottleneck analysis
Week 2: Async architecture plan and migration scaffolding
Week 3–4: Routing, structured outputs, and pipeline tuning
Week 5–6: Parallel context gathering and reliability hardening
Week 7–8: Benchmark iteration, rollout strategy, and enablement
Results
Up to ~40% latency reduction on benchmarked chat flows
Faster average responses (multi-date benchmark improvements validated)
Increased throughput capacity via async request handling
Business Value
Improving latency increased product usability and engagement potential while reducing infrastructure pressure during peak usage. The platform gained a scalable foundation to ship new AI features faster, support higher concurrency, and protect retention by making the chat experience consistently responsive.
Why SFAI Labs
SFAI Labs delivered impact quickly by combining AI Product Strategy with hands-on engineering execution. Our lab model prioritized measurable outcomes, fast validation, and production-grade reliability—aligning technical changes directly to user experience and commercialization goals.

B2C Startup (Confidential)
FAQ
What does SF AI Labs do?
SFAI Labs exists to help organizations turn bold ideas into real, scalable AI systems. We operate as an applied AI lab, combining rapid experimentation with disciplined execution to create technology that delivers lasting business and social value.
Who can work with SF AI Labs?
We partner with founders, operators, and enterprise leaders who want to use AI thoughtfully and responsibly to solve meaningful problems and build enduring organizations.
What kind of AI products does SF AI Labs build?
We design and build custom AI systems that augment human work, unlock hidden insights, and transform complex operations into intelligent, adaptive systems.
How long does it take to develop an AI prototype?
Our lab model allows most teams to move from idea to working prototype in four to eight weeks, creating early proof while laying the foundation for long-term impact.
Do I need a technical team to work with SF AI Labs?
No. We embed with your team as an extension of your organization, bringing research, engineering, and design together to turn ambition into working systems.



